Anu Shrestha

About
I am a Data Scientist with industry and research experience in Machine Learning, Deep Learning, NLP, Social Network Analysis, and Graph Neural Networks. I graduated from Boise State University with a Ph.D. degree in Computer Science in spring 2022 where I was a part of the AIBS lab working under Dr. Francesca Spezzano. My research focuses on the characterization and mitigation of false information on the web. The main goal of my research was to proactively combat false information by advancing towards the knowledge and understanding of false information and possible mitigation strategies. Over the course of my Ph.D. research, I got hands-on experience working with social media data from Twitter, online forums, and review-based platforms like Yelp and Amazon for understanding the actors responsible for false information creation, spread, and the victims of such false information.
In addition, I have worked as a Machine Learning Intern at Pacific Northwest National Laboratory (PNNL) working on result reproduction and error analysis of state-of-the-art systems in named entity recognition. I also gained industry experience as Intern Data Scientist at The Climate Corporation where I worked on a project to benchmark machine Learning models including statistical to neural network models for yield prediction.
Portfolio
Applied Deep Learning
LSTM Autoencoder based Framework
Detect Fraudulent Users in e-Commerce Platforms
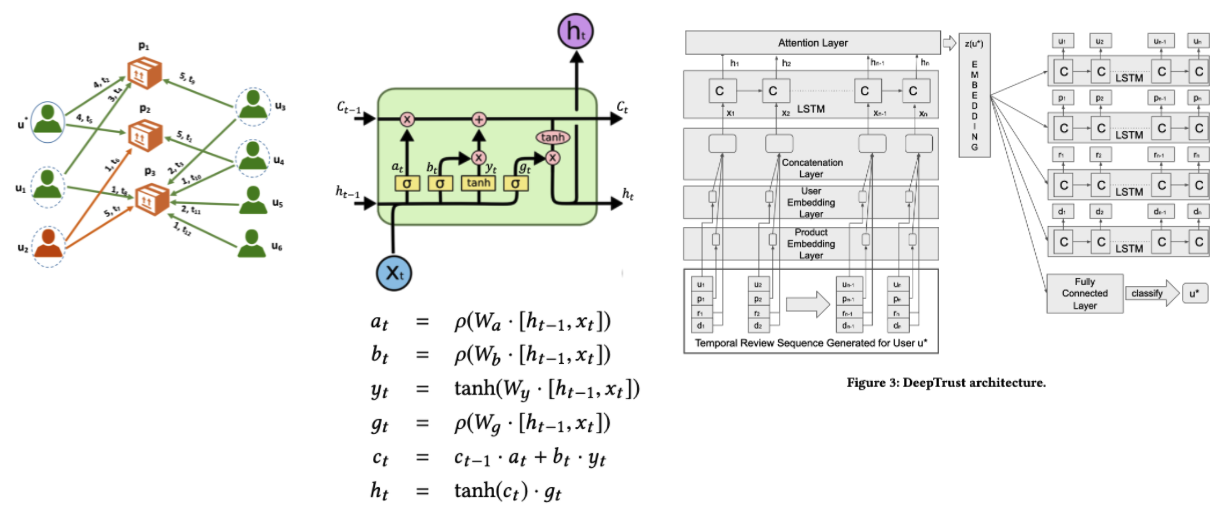
DeepTrust An unsupervised deep recurrent neural network based model build to generate embeddings aggregating temporal information: we consider users’ behavior over time, as they review multiple products. We model the interactions of reviewers and the products they review using a temporal bipartite graph and consider the context of each rating by including other reviewers’ ratings of the same items. We carry out extensive experiments on a real-world dataset of ~14k Amazon reviewers to detect trustworthy, unreliable and fraudulent reviewers with 93% F1 score, an improvement of at least 3% over the SOTA approaches.
Identify Depressed Users in Online Forums
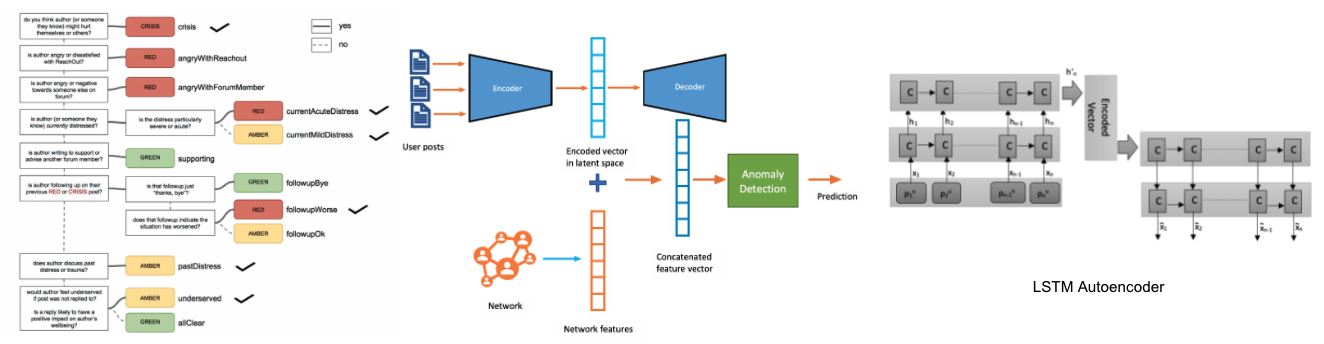
We address the problem of detecting users at risk of depression in online forums and use unsupervised techniques with (1) psycho-linguistic features describing the linguistic style of the user posts and the emotions expressed in them and (2) user networking behavior in the “who replies to whom” network extracted from the forum posts. Specifically, we propose a multi-modal methodology where a user embedding is first computed from the sequence of their posts via recurrent neural networks in an unsupervised fashion and, then, combined with user networking behavior. Finally, unsupervised anomaly detection is performed on these features to classify ~2k users as depressed or not achieving an F1-measure of 64% (3% higher than baselines).
Statistical Analysis and Machine Learning
Investigating How Readers Identify the Reliability of News
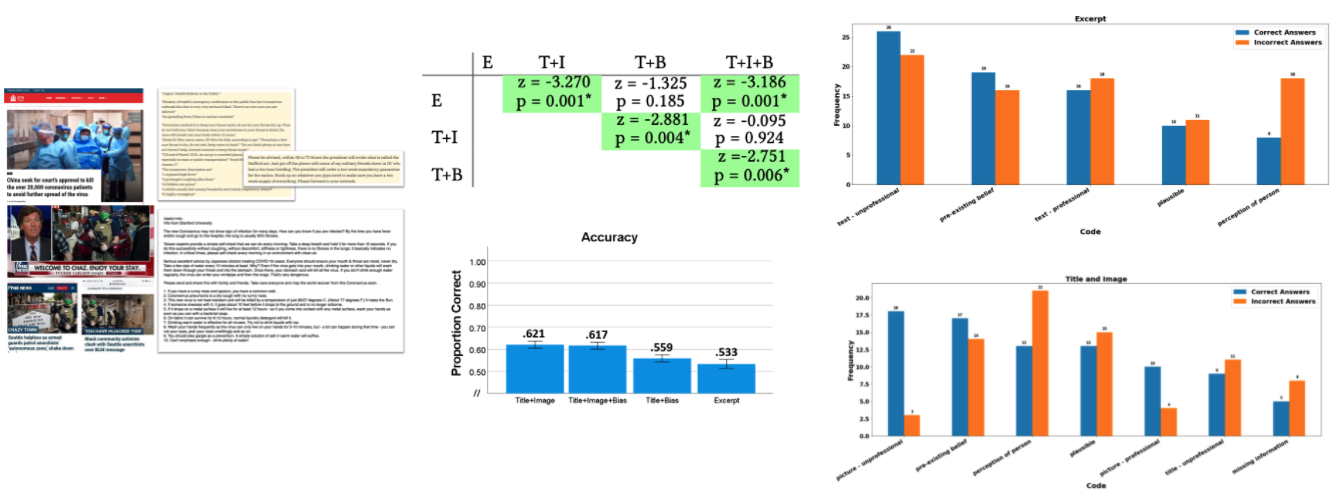
We investigated how various article elements (news title, image, source bias, and excerpt) impact users’ accuracy in identifying real and fake news. We also compared human performance to automated detection based on the same article elements and found that automated techniques were more accurate than our human sample while in both cases the best performance came not from the article text itself but when focusing on some elements of meta-data.
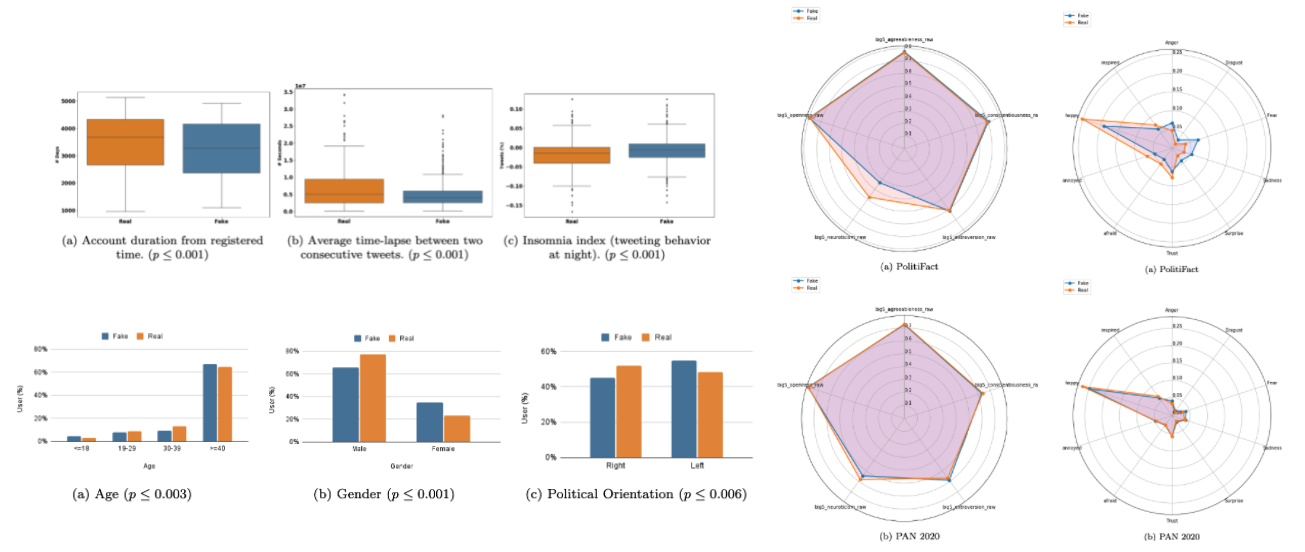
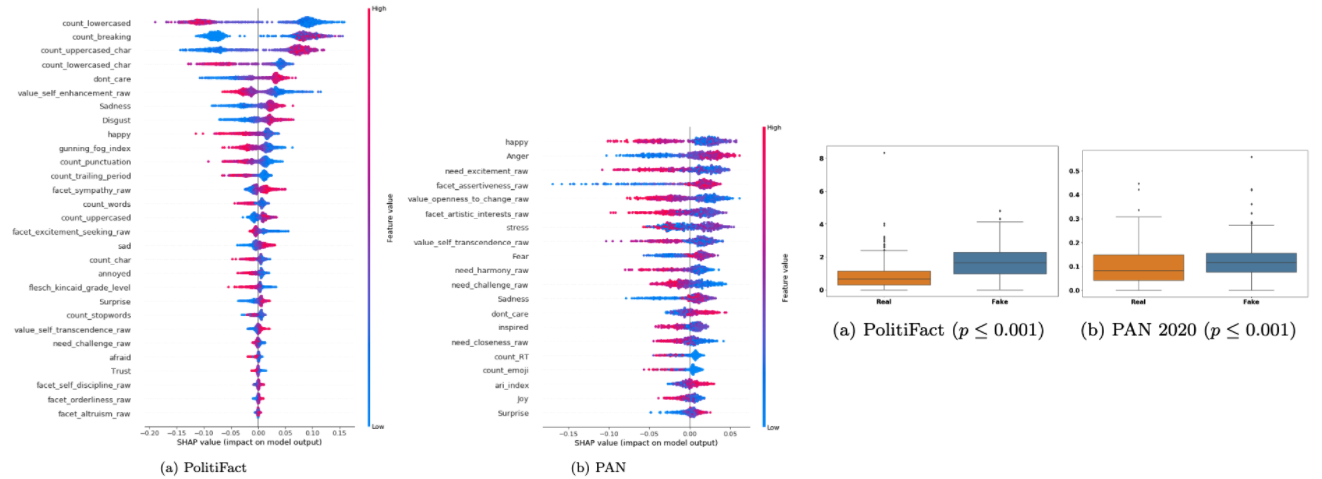
Characterizing and Predicting Fake News Spreaders in Social Networks
We perform a comprehensive analysis on two different datasets collected from Twitter and investigate the patterns of user characteristics in social media in the presence of misinformation. Specifically, we study the correlation between the user characteristics and their likelihood of being fake news spreaders and demonstrate the potential of the proposed features in identifying fake news spreaders.
Robustness of Recommender System
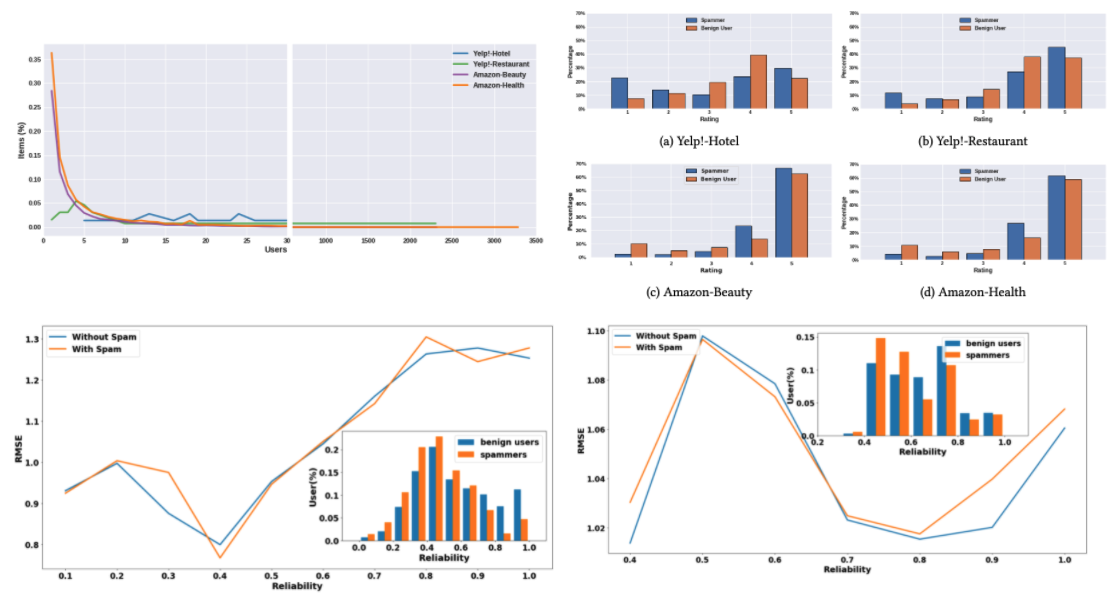
An Empirical Analysis of Collaborative Recommender Systems Robustness to Shilling Attacks
We present the results of an extensive analysis conducted on multiple real-world datasets from different domains (~40k Yelp reviewers and ~480k Amazon reviewers) to quantify the effect of shilling attacks on recommender systems. We focus on the performance of various well-known collaborative filtering-based algorithms and their robustness to different types of users. Trends emerging from our analysis unveil that, in the presence of spammers, recommender systems are not uniformly robust for all types of benign users.